
Process management is one of the most fundamental aspects of an operating system. In Linux, processes drive everything from user applications to system services, making efficient management crucial for performance, security, and stability. Understanding how Linux handles processes provides valuable insight into OS internals, enabling developers and system administrators to optimize resource utilization and troubleshoot complex system behavior.
This article provides an in-depth exploration of process management in Linux, covering process creation, memory layout, process states, context switching, and process termination.
What is a Process?
In Linux, a process is an active instance of a program in execution. When a command or application is launched, the operating system creates a corresponding process to manage its execution. Each process operates in its own isolated environment, with dedicated memory, system resources, and execution context, ensuring stability and security within the system.
Process vs. Thread
While both processes and threads represent execution units, they differ in key ways:
- Process: Each process has its own address space, meaning it does not share memory with other processes. This isolation enhances security and stability but comes with higher overhead.
- Thread: A thread is a lightweight execution unit within a process that shares the same memory space. Multiple threads within a process can run concurrently and communicate efficiently.
Every process in Linux is uniquely identified by a Process ID (PID), which the OS assigns upon creation. The PID allows the system to track and manage processes throughout their lifecycle.
Process Creation in Linux
In Linux, processes are created using the fork() system call, often followed by exec() to execute a new program. The process creation flow consists of the following steps:
1. Parent Process Calls fork()
The fork() system call creates a new child process by duplicating the parent’s memory, file descriptors, and execution context.
2. Child Process Execution
The child process can either continue executing the same code as the parent or replace its memory space with a new program using exec().
3. Process Control with wait()
The parent process can call wait() to suspend execution until the child process completes, ensuring proper synchronization.
This mechanism allows Linux to efficiently manage multitasking and process isolation.
Example: Process Creation in C
#include <stdio.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
printf("Child Process (PID: %d)\n", getpid());
} else {
printf("Parent Process (PID: %d)\n", getpid());
}
return 0;
}
Process Creation System Calls
| System Call | Description |
fork() |
Creates a child process by duplicating the parent. |
exec() |
Replaces the current process image with a new program. |
wait() |
Parent process waits for child process to complete. |
clone() |
Creates a new process or thread with specific flags. |
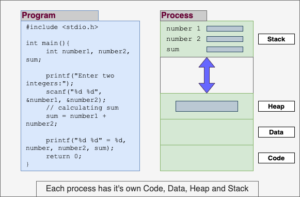
Process Memory Layout
Each process in Linux has a well-defined memory structure divided into different segments:
1. Code Segment (Text Section)
- Stores the compiled program’s instructions.
- Usually read-only to prevent accidental modifications.
2. Data Segment
- Holds global and static variables.
- Divided into initialized and uninitialized (BSS) sections.
3. Heap Segment
- Dynamically allocated memory (e.g., using
malloc()). - Grows upward in memory.
4. Stack Segment
- Stores function calls, local variables, and control flow information.
- Grows downward in memory.
Process States and State Transitions in Linux
A process in Linux undergoes multiple state transitions throughout its lifecycle. Understanding these states is crucial for effective process management, debugging, and performance optimization.
Process States in Linux
| State | Description |
|---|---|
Running (R) |
The process is actively executing on a CPU. If a system has multiple cores, multiple processes may be in this state simultaneously. |
Ready (R) |
The process is ready to run but is waiting for CPU time. The scheduler determines when it moves to the running state. |
Blocked (Sleeping) (S or D) |
The process is waiting for an event, such as I/O completion or a signal. Sleeping states are further classified as: – Interruptible Sleep (S): The process can be woken up by signals or events. – Uninterruptible Sleep (D): Typically used for disk I/O, where the process cannot be interrupted until the operation completes. |
Stopped (T) |
The process is paused, usually by a signal such as SIGSTOP, SIGTSTP, or for debugging purposes (ptrace). It can be resumed with SIGCONT. |
Terminated (T) |
The process has finished execution or was forcefully killed (SIGKILL). It will be removed from memory. |
Zombie (Z) |
The process has completed execution, but its parent has not yet collected its exit status. It remains in the process table until the parent retrieves it using wait(). |
Process State Transitions
A process transitions between these states based on system events, user actions, or kernel scheduling decisions.
- Creation (
fork()) → A new process is created in the Ready state. - Scheduling (
scheduler) → Moves the process from Ready to Running. - Blocking (
I/O wait()) → Moves from Running to Blocked when waiting for I/O or a resource. - Preemption (
time slice expires) → Moves from Running back to Ready if the CPU time slice ends. - Stopping (
SIGSTOP) → Moves from Running to Stopped when a signal is received. - Resuming (
SIGCONT) → Moves from Stopped back to Ready when continued. - Termination (
exit()) → Moves from Running to Terminated when execution completes. - Zombie (
exit() without wait()) → A child process enters the Zombie state if the parent does not collect its exit status.
These state transitions ensure efficient CPU utilization, process isolation, and controlled execution flow in a multitasking Linux environment.
Context Switching: How Linux Manages Processes
Context switching is the mechanism by which the CPU saves the state of a running process and loads the state of another process. This ensures that multiple processes can share the CPU without interfering with each other.
A context switch can occur in the following scenarios:
- Multitasking: The scheduler switches between processes to ensure fair CPU allocation.
- Interrupt Handling: The CPU temporarily switches to handle interrupts (e.g., hardware or software events).
- User-Kernel Mode Transition: When a system call is made, the CPU switches from user mode to kernel mode and back.
Steps in Context Switching
Context switching involves saving the current process state and restoring the next process state. The key steps are:
1. Saving the Current Process State
- Store CPU registers, including the program counter (PC), stack pointer (SP), and general-purpose registers.
- Save the process control block (PCB), which holds metadata like process ID, state, and scheduling information.
2. Selecting the Next Process
- The CPU scheduler selects the next process to run based on scheduling policies (e.g., round-robin, priority-based scheduling).
3. Restoring the New Process State
- Load the saved state of the selected process from its PCB.
- Restore CPU registers and program counter.
4. Resuming Execution
- The CPU continues execution from the point where the new process was last paused.
This switch happens so quickly (typically in microseconds) that users do not notice it, enabling smooth multitasking.
Context Switching Overhead
While necessary for multitasking, context switching introduces overhead due to:
- CPU Cycle Consumption: Saving and restoring process states takes CPU cycles, reducing the time spent on actual execution.
- Cache Flushes: The CPU cache may need to be invalidated when switching processes, affecting performance.
- Increased Latency: Frequent switches can cause performance degradation, especially in systems with heavy multitasking.
Optimizing Context Switching
To minimize the impact of context switching, Linux employs:
- Efficient Scheduling Algorithms: Modern schedulers like CFS (Completely Fair Scheduler) reduce unnecessary switches.
- Processor Affinity: Keeps processes bound to specific CPUs to minimize cache invalidation.
- Kernel Thread Optimization: Reduces context switches by handling lightweight tasks within kernel threads.
Monitoring Context Switching
Linux provides tools to analyze context switch frequency and identify performance bottlenecks:
vmstat– Displays system-wide context switch statistics.
vmstat 1 5 # Shows CPU context switches per second
perf– Measures context switch impact on CPU performance.
perf record -e context-switches -a sleep 5 perf report # Displays context switch events
pidstat – Monitors per-process context switch activity.
pidstat -w 1 # Shows voluntary and involuntary context switches
Process Termination
A process may terminate normally (after completing execution) or abnormally (due to a signal or error).
Ways a Process Can Terminate
| Method | Description |
|---|---|
exit() |
Process terminates normally |
kill(pid, signal) |
Sends a signal to terminate a process |
abort() |
Abnormally terminates the process |
return from main() |
Implicitly calls exit() |
Zombie and Orphan Processes
- Zombie Process: A terminated process that remains in the process table because the parent hasn’t collected its exit status.
- Orphan Process: A child process whose parent has terminated; it gets adopted by
init.
Wrapping Up
Process management is a cornerstone of Linux internals, ensuring efficient multitasking, resource allocation, and security. Understanding how Linux handles processes—from creation and memory management to state transitions and termination—enables system administrators and developers to optimize performance and troubleshoot complex issues.